
Life could be a lot easier for technical teams in consumer businesses. As data owners, it’s their job to make customer data a valuable asset for the business, but the dominant practices are manual and repetitive.
Part of this has to do with the complexity that’s unique to customer data: the volume and velocity from across channels is massive, it’s always changing as people go through life and their preferences evolve, and it’s subject to a patchwork of regulations. Yet customer data is only valuable to a company if it’s accurate, up-to-date, secure, and accessible to business teams for appropriate use.
Adding to the data modeling and management challenge is the fact that it’s never one-and-done, but rather needs to be repeated over and over again. New data sources, new destinations, new models, new regulations, not to mention new information about existing customers, all of which results in a never ending stream of change requests from business teams. Bottom line, data assets needs constant updates and maintenance.
This collection of jobs to be done is extremely time- and resource-intensive when approached manually. The unfortunate reality is that data engineers and CTOs are used to this manual method. Most tools dealing with customer data leave data quality and fidelity upkeep to the practitioners. Properly unifying the data requires maintaining both merge rules and match rules, with lots of custom code jobs to make it work. The dominant mindset is that the only ways to approach this challenge are more elbow grease and better processes.
The good news is that the AI revolution offers approaches that can make data modeling and management more efficient, more cost effective, and more successful at driving better business results. New methods mean that it doesn’t have to be like Sisyphus pushing his boulder up the hill day in and day out.
The real time-cost of data modeling & management
It’s worth backing up to take in a full view of all the jobs and sub-jobs involved in making customer data a valuable asset.
Co-locate all of your customer and behavior data
Model and clean data
Resolve identities
Merge into unified profile
Link new identity back to behavior data
Generate business-level aggregated data
Build views for marketers (and other stakeholders)
Feed resulting customer profiles into action applications
Manage change on an ongoing basis
And these phases are really just subject headers that contain multiple sub-steps, each representing hours of work for your teams. Much of this work requires time-intensive custom coding since standard customer data tools don’t account for these capabilities.
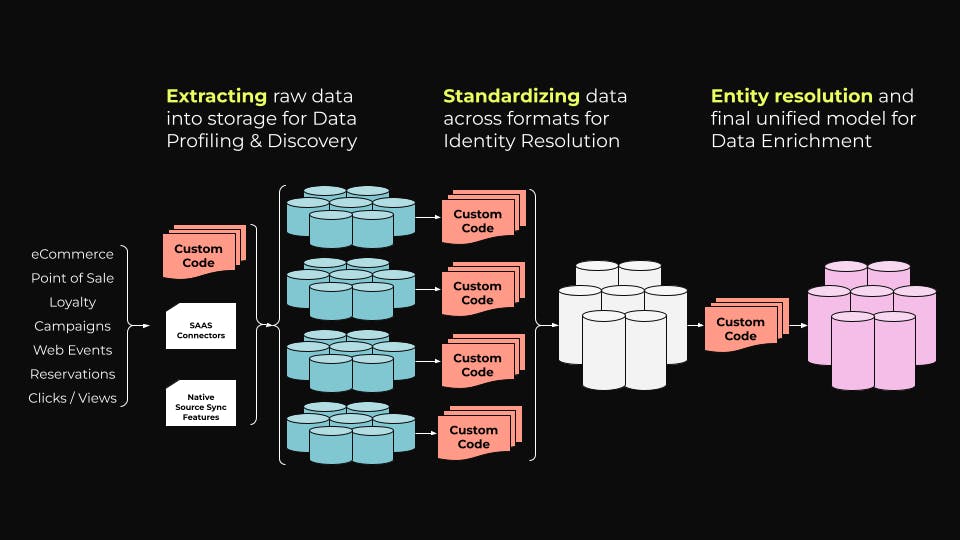 Legacy data refinement needs extensive custom code.
Legacy data refinement needs extensive custom code.For example, let’s zoom in on phase 2 in the list above, Model and Clean Data, to take a more granular look at the sub-tasks involved and the time they typically take to perform.
We’ll say that this is working with a data infrastructure that involves 5 identity feeds (eCommerce profiles, point of sale profiles, loyalty profiles, campaigns, clicks/views) and 5 behavior parameters (in-store purchase, online purchase, email, customer support, social media engagement).
2. Model and Clean Data
Jobs to be developed | Example level of effort per table |
|---|---|
Convert source data models into a format that works well with identity resolution process | 16 hours |
Extract customer table from behavior tables if necessary | 16 hours |
Identify bad PII values | 8 hours |
Define data standardization and cleaning rules | 8 hours |
QA data standardization and cleaning rules | 8 hours |
QA data modeling | 8 hours |
Total per table | 64 hours |
Total for 5 tables | 320 hours |
320 hours for one phase of the process, involving six sub-steps. Each of the other eight phases has between four and ten sub-steps. A conservative estimate for the entire process would be upwards of 1,200 hours to onboard and ~200 hours per change (get in touch, I’ll be happy to walk you through it step by step), and that’s assuming there are no complications along the way.
Where AI tools can save you hours, days, weeks
One of the main reasons why the legacy method of data modeling is so labor intensive is all the custom code jobs. At several points in the process, data engineers need to write code to move data between locations, standardize data formats, and build models. For each of these areas, AI tools built for these jobs can turn a manual process into an automated one, drastically reducing the amount of manual work and the time involved.
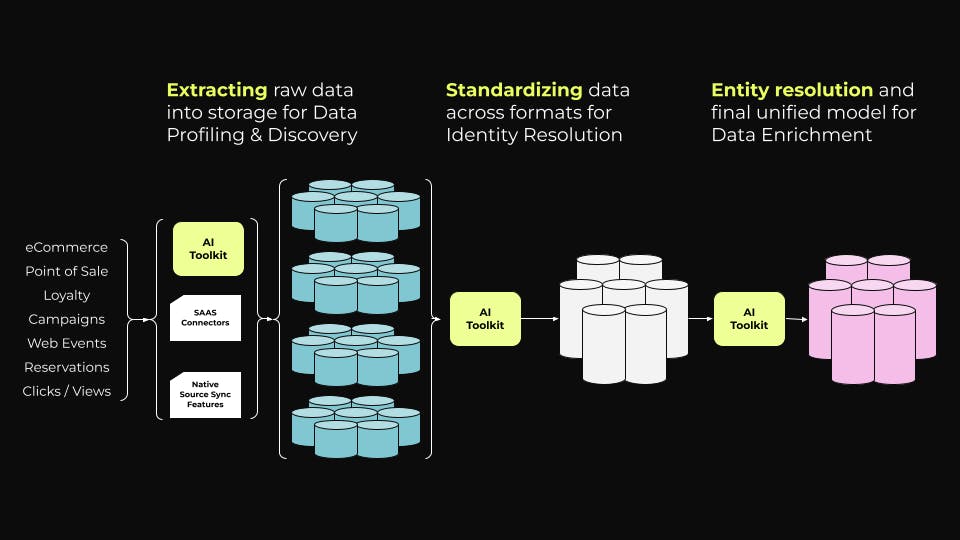 AI tools dramatically reduce custom code to make data refinement faster.
AI tools dramatically reduce custom code to make data refinement faster.This is especially helpful since so many of these processes need to be done over and over again — data infrastructure is never set-it-and-forget-it. Beyond routine maintenance, the tech teams responsible need to repeatedly revisit key phases to account for new data sources and destinations, new models to meet new business requirements, updates in customer profiles due to new behaviors or life changes, etc.
Let’s take another look at phase 2, Model and Clean Data, and how AI automation can substantially reduce the burden on tech teams to perform manual coding jobs.
Job to be done | Legacy method - example level of effort per table | AI toolkit - example level of effort per table |
|---|---|---|
Convert source data models into a format that works well with identity resolution process | 16 hours | AI analyzes and annotates data with validation by user: 30 minutes |
Extract customer table from behavior tables if necessary | 16 hours | AI analyzes and annotates data with validation by user: 30 minutes |
Identify bad PII values | 8 hours | AI ID Resolution and OOTB rules identify common patterns with an option to customize: 30 minutes |
Define data standardization and cleaning rules | 8 hours | AI ID Resolution provides a framework, only manual work is any customizations: 30 minutes |
QA data standardization and cleaning rules | 8 hours | 4 hours |
QA data modeling | 8 hours | 4 hours |
Total per table | 64 hours | 10 hours |
Total for 5 tables | 320 hours | 44 hours |
That’s an 86.25% improvement in time needed to complete this phase. Again, extrapolating this through the rest of the onboarding process and we go down from over 1200 hours to ~350 hours. There are some elements that AI automation cannot account for and still need to be taken care of by data engineers, generally anything that requires human oversight for QA or involves strategic choices about what kinds of attributes or marketing use cases to build for. But the tedium of extensive custom code jobs is taken out of the picture.
Tech teams don’t need to struggle to unlock the value of customer data
The next AI revolution for consumer businesses is in making persistent data quality a reality. There are more customer apps generating more data than ever before, and technical leaders need a shortcut to prepare and organize customer data. Rules-based approaches have never been easy or reliable, but today’s profusion of data makes them truly obsolete. In order to succeed in data modeling & management – creating and maintaining a data asset of high enough quality and easy enough access to be of value to the business – technical teams need methods that offer a dramatic boost in both efficiency and effectiveness.
Implementing an AI toolkit to replace custom code jobs and rules-based approaches means:
Faster time to value by removing complexity
Lower costs through automation
Better results from higher-quality data
Generative AI, data governance, and personalization will only be successful if businesses can build a high-quality data foundation. Accomplishing that means moving away from incremental process improvements for cumbersome legacy methods and instead taking advantage of advancements in AI tooling for customer data. It will make the work far faster and the outcome much more valuable.