
For tech leaders whose job is to manage customer data infrastructure, I have good news: lakehouse architecture will make things so much easier.
I know from talking with brands that putting customer data to work has often meant inefficiencies in cost and effort. With older generations of big data environments like warehouses and lakes, tech stacks and data systems often became a collection of silos, forcing brands to either settle for what they could do within each silo or to perform complex ETL operations to move data across silos.
This meant poor data quality and complicated governance (not to mention stressed-out data teams).
That can all change with lakehouse architecture and new data sharing methods based on open-source table formats like Delta Tables and Apache Iceberg.
When systems store data natively in lakehouse formats, support open lakehouse sharing protocols, and are part of the common lakehouse catalog, maintaining data quality and governance across platforms and tools is no longer a problem. This represents a major leap forward in flexibility and cost optimization.
So how did we get here? And what does it look like in practice?
The evolution of the lakehouse
The data lakehouse answers the shortcomings of its predecessors, the data warehouse and the data lake. Warehouses started out on-premises in the 1990s, able to deal with structured data and perform SQL analysis, but they lacked flexibility and had a high administrative cost due to requiring physical infrastructure. The SaaS offerings of data lakes and cloud data warehouses came about as the variety and volume of data increased into the 2010s, and they addressed new needs: ability to tightly interoperate with cloud services, optimization for analysis with AI/ML, and in the case of data lakes, support for unstructured and semi-structured data. Perhaps most significantly from an infrastructure standpoint, data lakes decoupled storage and compute. But they also had their problems when it came to security and governance: operations often involved substantial complexity, and it was difficult to manage who had access to what data.
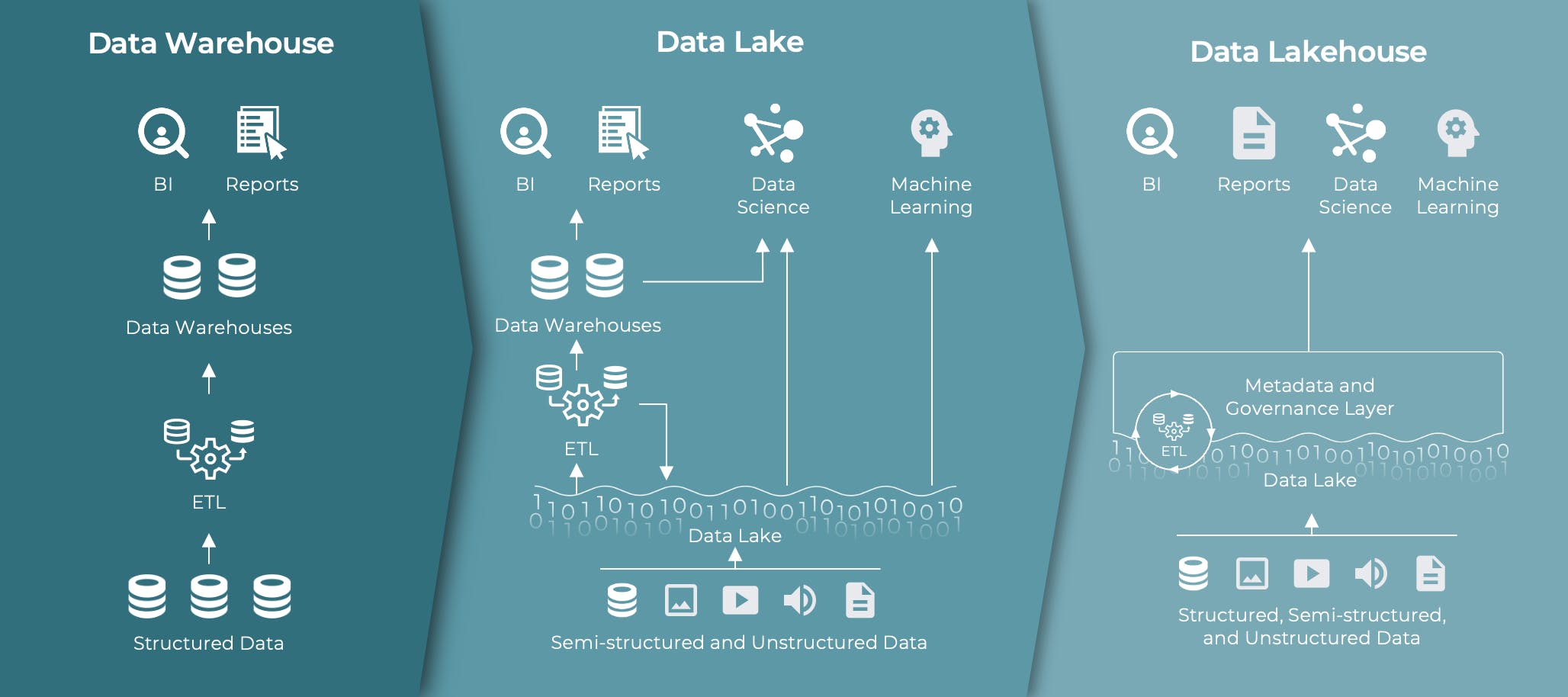
Most troubling of all were the silos between environments. Brands often have multiple big data environments in their infrastructure, because they want the best-of-breed solution for every workload. They may prefer Snowflake for database workloads and Databricks for AI and ML workloads. They may have marketing audience data in BigQuery and financial data in Azure Synapse. To consolidate and manage these they would have to go through a complex migration process to move everything to a single environment, compromising the effectiveness of each tool and adding time and complexity without benefit.
What was needed was something that provided the massive scale and flexibility of the data lake while eliminating the specialized storage and governance required to use best in class tools.
This is what gave rise to the lakehouse architecture: data is stored in open formats like Delta Tables, Iceberg Tables, and Parquet files, while compute happens locally in each environment in the infrastructure. Each format has data pipelines that let live data be shared at rest, allowing data teams to create cross-platform workflows without needing to develop and maintain integrations or copies between each platform. That means no more silo headaches or time lost ferrying data.
How the open-format lakehouse makes customer data work better
Data sharing through open formats and protocols enabled by lakehouse architecture means teams are able to work much more efficiently and effectively, leading to a number of benefits:
Persistent data quality across the stack – Each tool using a common lakehouse architecture can share enriched data in a Lakehouse Catalog. This allows every other tool using lakehouse architecture to access the data without copying the data from tool to tool.
Flexibility in building the best stack – IT teams can build a best-of-breed stack by using each tool for its intended purpose without any concerns of data replication.
Reduce cost and effort – Businesses can choose where to process and store data to maximize efficiency.
The benefits above all connect to the same overarching principle: When customer data is shared between platforms through the lakehouse, it eliminates hundreds of hours of effort for technical teams in building and maintaining processes to do the copying, formatting, and integrations. Without all that ETL development, teams can stop integrating and start putting the data to work.
An architecture for today’s data needs
The open lakehouse format and the data sharing it enables represent a sea change (lake change?) because they offer solutions to the challenges data managers have been struggling with for so long.
Data security and governance become more reliable and straightforward without the need to copy data from tool to tool and manage multiple points of access. When the data lives in one secure location and is shared out without copying, the risk of data breaches goes down dramatically.
Compliance is easier when there’s clear visibility into where all customer data is actually stored, so that data managers can follow laws like GDPR and CCPA. This will make it much simpler to respond to a “right to forget” request.
Personalization and Generative AI become possible when teams are able to act on massive data sets scaled across multiple tools and platforms. In the old architecture paradigm every ETL would slow down this process and add lag to the customer experience, but in a lakehouse environment this is no longer an issue.
The lakehouse is a massive evolution for customer data as it’s the first setup to truly remove silos, maximizing flexibility while preserving data quality and strong governance. For data teams, this means lower cost and higher efficiencies, and for business teams it accounts for the data volume, speed, and quality needed to serve the best customer experiences. Open sharing in the lakehouse pushes the boundaries on the possibilities for customer data, and is set to become the industry standard.
Learn more about sharing customer data across big data environments in our on-demand webinar.